初めまして。柏寧有葉 / alphaRomeo323 と申します。
今回は、Youtubeの最新動画を取得して返すサーバーレス関数を実装してみました。
この記事は、VTuber・バーチャルプログラマ・技術者 Advent Calendar 2023の19日目の記事です。
はじめに
このサーバーレス関数を開発しようと思った直接のきっかけが、Xの仕様変更でYoutubeのURLが入ったポストが非表示になる案件ですね。
どうやらはじいてるのは文章にhttps://youtube.comが入っている時だけみたいです
これを知って、「自分が持ってるドメインにアクセスさせて、URLにリダイレクトをかければいいのでは!?」と思うようになりました。
また、このブログのトップページに最新動画を表示させたいなと思い、いつものコミュニティの知人に相談したところ
Cloudflareのサーバーレス関数を使ったらどうだ?
とご紹介された次第。
皆さんも「最新動画を常に見てもらいたい!でも差し替えるの面倒だな……」と思うこと、あるかもしれませんので、ぜひ参考にしていただけたらと思います。
一応イベントものですし、ITに疎い方にも実践していただきたいので、コメントや解説多めにしておりますが、わからない部分がありましたらごめんなさい。
Cloudflare Workersのセットアップ
まずどこのご家庭にもあるであろうCloudflareアカウントを用意しておきましょう。
まさかない方はいらっしゃらないと思いますが、 持ってない方向けの作成方法はこちらです。
wrangler
続いて、Cloudflare Workersは、CLIで簡単に編集・確認・デプロイができるwranglerというアプリが提供されています。 node.jsの環境で使えるので早速ダウンロード
npm install -g wranglerこれで、
wrangler loginを入力するとブラウザでCloudflareのページが開き、適当に認証を行えば簡単にCloudflare Workersにアクセスできちゃいます。
早速プロジェクトを立ち上げます。今回はTypeScriptを使って開発するので、すべてyesで通せる-yオプションを使っています。
wrangler init -y youtube-redirectJavaScriptの場合は手動で選ぶ必要があるので-yを外してください。
これでカレントディレクトリ配下にyoutube-redirectフォルダができるとともに、CloudflareダッシュボードのWorkers & Pagesにもyoutube-redirectが用意されます。
以降はそのyoutube-redirectディレクトリ下で作業を行います。
Youtube Data APIを叩いて最新動画を取得する
Cloudflare Workersではnodeモジュールは使えません。
今回は普通にAPIをGETメソッドで叩き、結果からVideoIdを抜き出してリンクに仕立て上げ、リダイレクトを行います。
APIキーの準備
APIキーはGoogle Cloudから入手することができます。
適当にプロジェクトを立ち上げ、"APIとサービス > 認証情報"より新規の認証情報を作成します。
どういうタイプのものを作るか聞かれるので"APIキー"と答えてください。
生成したAPIキーは、念のためYouTube Data API v3に用途を制限しておくとグッド。
APIキーを秘匿された環境変数に通す
APIキーをコードにベタ書きすると、悪用されるリスクが危険でヤバイ(支離滅裂な表現)。ということで、秘匿された環境変数(Secrets)に通してあげます。
Cloudflare Workersにもちゃんとそういう機能が用意されています。
まずはローカルな環境から。.dev.varsに変数を準備します。
YOUTUBE_API={ Your API Key }続いて、本番環境ですが、wrangler secretコマンドで行います
wrangler secret put YOUTUBE_API ⛅️ wrangler 3.21.0
-------------------
✔ Enter a secret value: … ***************************************
🌀 Creating the secret for the Worker "youtube-redirect"
✨ Success! Uploaded secret YOUTUBE_APIこれ設定完了です
コードを書く
大まかな流れは
- APIを叩いてチャンネルの最新動画を検索する
- 検索結果がjsonで飛んでくるので、オブジェクトに落とし込む
- オブジェクトから1番目のVideoIDを抜き出す
- https://youtu.be/ の末尾にVideoIdをくっつけてResponseオブジェクトを作成する
- Responseオブジェクトを返す
という感じです。
APIのリファレンスはこちらを参照してください。
というわけでサンプルコードです
export default {
async fetch(request: Request, env: any, ctx: any) {
const channelId = "";//Your channel id here
const url = `https://www.googleapis.com/youtube/v3/search?key=${env.YOUTUBE_API}&part=id&type=video&order=date&maxResults=1&channelId=${channelId}`;//APIを叩くためのURL
let id: string;
let res: Response;
await fetch(url,{ //fetchで叩く
method:"GET"
}).then((result) => result.json().then((data)=>{ //jsonで返ってくるのでオブジェクトに落とし込む
id = data.items[0].id.videoId;
res = Response.redirect(`https://youtu.be/${id}`, 302); //リダイレクトするレスポンスを作成
})).catch((err) => {
res=new Response(err.message, {status: 503}); //失敗したら代わりに503レスポンスを生成
});
return res; //レスポンスを返す
},
};ChannelIdはできれば環境変数に通してやってください。 (のちに登場するttlも同様)
注意として、基本的に用意されている関数は非同期のものが多いため、ちゃんとawaitで待機してあげる必要があります。
テスト実行とデプロイ
テスト実行のコマンドはこれ
npm start起動した際に割り当てられるポートはランダムです。
起動したらbキーでブラウザを開いて確認ができます。
デプロイする際はこれ
npm run deployCurrent Deployment IDが出されるので控えておきましょう。ロールバックに必要です。
Youtube Data APIを節約する
Youtube Data APIは1日10000リクエストの制限が初期でかかっております。
searchには100のリクエストを消費するため、このままでは100回しか踏めないリンクと化してしまいます。
それでは不便なので、以下のような節約策をとりましょう
主な方法は2つあります
- CloudflareのCache APIにレスポンスをキャッシングさせる
- Cloudflare D1 DatabaseにURLを一時保存する
ブラウザのCache APIにレスポンスをキャッシングさせる
Cloudflare WorkersではCache APIという、ブラウザのキャッシュ機能を模したAPIが用意されております。
これを利用することによって302なら(何も設定しないで)20分間キャッシングしてくれます。
これなら大量にアクセスされても、日100*60/20*24=7200のAPIリクエストで済みますね。
またキャッシングすることで、2回目以降より高速にアクセスできるようになります。

こういう人におすすめです
- Cloudflareで自分のドメインを管理している(必要条件)
- Youtubeチャンネルは1個だけでやっている
- 海外アクセスも多くない
- プログラミング初心者でデータベースなんかわからない
実装
先ほどのコードに手直しを入れるだけです。
export default {
async fetch(request: Request, env: any, ctx: any) {
const channelId = "";//Your channel id here
const aplUrl = `https://www.googleapis.com/youtube/v3/search?key=${env.YOUTUBE_API}&part=id&type=video&order=date&maxResults=1&channelId=${channelId}`;//APIを叩くためのURL
const url = new URL(request.url) //アクセスしたURLをオブジェクト化
if(url.pathname !== '/'){
return new Response("inviled path: " + url.pathname, {status: 404}); //もしルートでなければ、無効なURLとして処理
}
const cacheKey = new Request(url.toString(), request); //キャッシュのkeyを生成
let res: Response, id: string;
res = await cache.match(cacheKey); //keyを使ってレスポンスを読み出す
if (!res) { //もしもキャッシュにレスポンスがなかったらYoutubeAPIを叩く
await fetch(aplUrl,{ //fetchで叩く
method:"GET"
}).then((result) => result.json().then((data)=>{ //jsonで返ってくるのでオブジェクトに落とし込む
id = data.items[0].id.videoId;
res = Response.redirect(`https://youtu.be/${id}`, 302); //リダイレクトするレスポンスを作成
ctx.waitUntil(cache.put(cacheKey, res)); //キャッシュに格納する
})).catch((err) => {
res=new Response(err.message, {status: 503}); //失敗したら代わりに503レスポンスを生成
});
}
return res; //レスポンスを返す
},
};カスタムドメインを設定する。
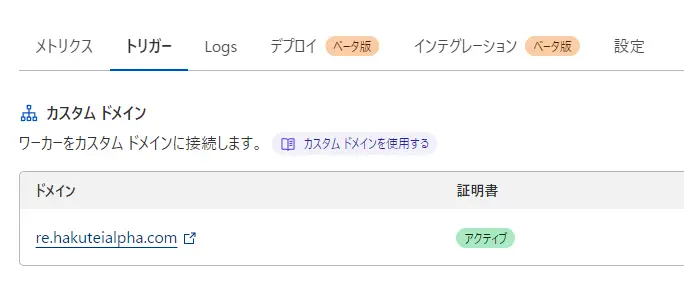
デプロイしたら、自分のWorkersにカスタムドメインを設定します。
ダッシュボードから目的のWorkersの画面に行き、"トリガー"からカスタムドメインを設定してください。
キャッシュ時間を延ばしたいとき
APIをもっと節約するためにキャッシュ時間を延ばしたい場合は、cache-controlヘッダを付け加えることで行えます。
しかしながら、Response.redirect()にはheadersを編集できる引数がありません。
また、Response.headersも読み取り専用です
よって以下のようにResponseオブジェクトを生成してあげる必要があります
const ttl = 3600 //sec //Time to live here
res = new Response(null, {
status:302,
headers:{
"Location": `https://youtu.be/${id}`,
"Cache-Control": `public max-range=${ttl}`
}
})Cloudflare D1 DatabaseにURLを一時保存する
Cloudflare D1 DatabaseはCloudflare Workersで使えるデータベースです。無料だと500MBしか使えませんが、URLを一時保存しておくだけならそれだけで十分でしょう。
Cache APIも併用できます。2段階でキャッシュしていこうな。
こういう人におすすめです。
- Youtubeチャンネルを複数持っている
- プログラミングに腕がある
- ほかのAPIも叩くといった複雑なこともさせたい
- Cloudflareで管理できるドメインを持っていない
データベースの準備
データベースはWranglerで生成できます。
wrangler d1 create redirect-url✅ Successfully created DB 'redirect-url' in region APAC
Created your database using D1's new storage backend. The new storage backend is not yet recommended for production workloads, but backs up your data via point-in-time restore.
[[d1_databases]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "redirect-url"
database_id = "{ 固有のID }"生成すると、wrangler.tomlに記述するためのコードブロックが出力されるため、忘れずにwrangler.tomlにコピペしてください。
次にデータベースの作成です。Urlsには相対パスをキーとして、リダイレクト先URL、生成日付を保存できるようにしておきます[1]。
また、Channelsには相対パスをキーとして、チャンネルIDを格納しておきます。
CREATE TABLE Urls (Pathname TEXT, Redirect TEXT, CreatedTime DATETIME, PRIMARY KEY (`Pathname`));
CREATE TABLE Channels (Pathname TEXT, ChannelId TEXT, PRIMARY KEY (`Pathname`));
INSERT INTO Urls (Pathname, Redirect, CreatedTime) VALUES ('/', 'https://www.youtube.com/', '2023-12-18T00:00:00.000Z'), ...;
INSERT INTO Channels (Pathname, ChannelId) VALUES ('/', 'Your ChannelID here'), ...;データはチャンネルの数用意しておきましょう。
というわけでまずはローカルに生成。
wrangler d1 execute redirect-url --local --file=./test.sql一応アクセスできるかチェック
wrangler d1 execute redirect-url --local --command='SELECT * FROM Urls'🌀 Mapping SQL input into an array of statements
🌀 Executing on local database redirect-url (679bc8da-f619-4efd-aeb6-94c07fa354e0) from .wrangler/state/v3/d1:
┌──────────┬──────────────────────────┬──────────────────────────┐
│ Pathname │ Redirect │ CreatedTime │
├──────────┼──────────────────────────┼──────────────────────────┤
│ / │ https://www.youtube.com/ │ 2023-12-18T00:00:00.000Z │
└──────────┴──────────────────────────┴──────────────────────────┘本番環境にデプロイするときは、--localオプションを外してやってください
wrangler d1 execute redirect-url --file=./test.sql実装
それでは書いていきましょう
export default {
async fetch(request: Request, env: any, ctx: any) {
const url = new URL(request.url); //アクセスしたURLをオブジェクト化
let res: Response;
res = await getRedirect(url, env); //リダイレクトURLを取得する関数↓
return res;
},
};
async function getRedirect(url: URL, env: any): Promise<Response> {
let res: Response, newUrl: string;
const ttl = 3600 //sec //Time to live here
const { results } = await env.DB.prepare(
"SELECT * FROM Urls WHERE Pathname = ?"
).bind(url.pathname)
.all(); //相対パスをキーにしてデータベースから情報を取り出す
if(!results.length){
return new Response("inviled path: " + url.pathname, {status: 404}); //もしデータベースに存在しないならば、無効なURLとして処理
}
const createdTime = new Date(results[0].CreatedTime); //データベースに記録された日時をオブジェクト化
const currentTime = new Date();
if(currentTime.valueOf() - createdTime.valueOf() < ttl * 1000) //TTLよりも時間が経っていなければ
{
newUrl = results[0].Redirect
res = Response.redirect(newUrl, 302); //データベースから取り出したURLでリダイレクトレスポンスを作成
}
else{ //TTLよりも時間が経過しているとき
const channelId = await getChannelId(url, env); //ここでもresultsを使うため別関数に分離↓
if(!channelId){
return new Response("Database Error", {status: 500}); //チャンネルIDがない場合サーバーエラーとして処理
}
res = await youtubeSearch(channelId, env); //YoutubeAPIを叩いてレスポンスを作る↓
if(res.status !== 302) {
return res //リダイレクトレスポンスでない場合そのまま返す
}
newUrl = res.headers.get('Location'); //Locationヘッダ内のURLを抜き出す
await env.DB.prepare(
"UPDATE Urls SET (Redirect, CreatedTime) = (?, ?) WHERE Pathname = ?"
).bind(newUrl, currentTime.toISOString(), url.pathname).run(); //新しいURL現在時刻を相対パスをキーにして格納
}
return res;
}
async function getChannelId(url:URL, env: any): Promise<string> {
const { results } = await env.DB.prepare(
"SELECT ChannelId FROM Channels WHERE Pathname = ?"
).bind(url.pathname)
.all(); //相対パスをキーにしてデータベースから情報を取り出す
if(!results.length){
return ""; //何もなかったら仕方ないので空文字列を返す
}
return results[0].ChannelId //チャンネルIDを返す
}
async function youtubeSearch(channelId: string, env: any): Promise<Response> { //さっきのコードのAPI叩く部分だけ分離した感じ。ノーコメント
let id: string;
let url = `https://www.googleapis.com/youtube/v3/search?key=${env.YOUTUBE_API}&part=id&type=video&order=date&maxResults=1&channelId=${channelId}`;
await fetch(url,{
method:"GET"
}).then((result) => result.json().then((data)=>{
id=data.items[0].id.videoId
})).catch((err) => {
return new Response(err.message, {status: 503});
});
return Response.redirect(`https://youtu.be/${id}`,302);
}おまけ
上記getRedirect()の最下段return前にこのコードを添えてみると…
if (url.searchParams.get('embed') === "true"){
res = Response.redirect(newUrl.replace(/youtu.be/g,"www.youtube.com/embed"), 302)
}Embedに対応できます!!!
というわけで、ホームページの最新動画はこのWorkersを使って表示させてます!(`・ω・´)
おわりに
今回は、Cloudflare Workersを使って、Youtubeの最新動画にリダイレクトするURLを作ってみました!!
感想としましては、node.jsってすごいんだなと改めて感じました。
普段使えてるライブラリがないだけでこんなに使い勝手が違うものかと。
ちなみにAPIを叩くのにfetch()を使う必要があると気づくまでが一番長かったです
でもその結果、自分のやりたかった「常にトップページに最新の動画が載ってるサイト」を構築できたので、個人的に満足です!
そんなに難しいこともしていないので、ITに疎い方も是非やってみてはいかがでしょうか。
謝辞
今回はこのようなサイトを参考にさせていただきました。
- サーバーレス入門。初めてでもわかるCloudflare Workersの書き方からデプロイまで。 https://reffect.co.jp/html/cloudflare-workers
- Cloudflare R2の画像をCache APIでキャッシュして返すメモ https://zenn.dev/syumai/scraps/d3468205fee0f0
- Cloudflare Workers から D1 を操作する https://zenn.dev/kameoncloud/articles/6264967e5fd1da
D1 Databaseの
DATETIMEデータ型の部分にはなぜかISO 8601形式で日付を入れられたのでこうなりました。こうすると暗黙でUTCになってくれるのでコーディングが楽になります。 ↩︎